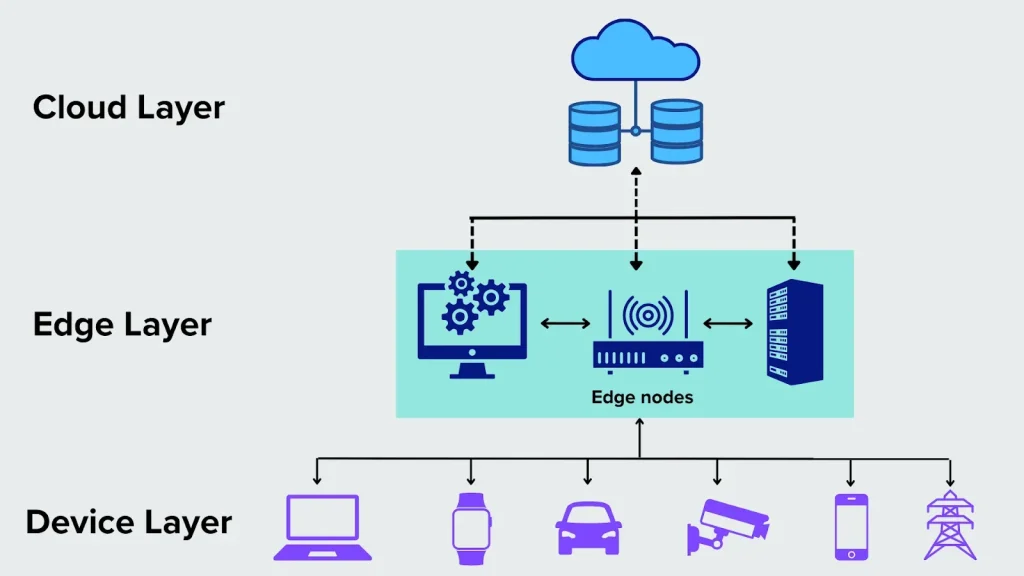
Edge computing is reshaping how we think about data, moving processing closer to the source to speed decision making. As the number of connected devices and sensors grows, edge data processing enables faster responses and reliability, unlocking benefits across industries such as manufacturing, logistics, and consumer electronics. By moving computation to the edge, organizations can leverage edge AI and real-time data processing at the edge to act on insights in milliseconds. This approach contributes to latency reduction, reduces bandwidth usage, and supports safer, more autonomous operations. Ultimately, the shift toward distributed processing makes data actionable faster while preserving cloud continuity and governance.
In practical terms, this shift resembles distributed computing at the network edge, where devices analyze data locally rather than sending everything to a distant cloud. You’ll also hear terms like near-data processing and on-device analytics, all pointing to the same goal of faster, privacy-preserving insights at the source. Other LSIs include edge-native architectures and fog computing, which describe architectures that place intelligence closer to data generation while maintaining a bridge to centralized resources. By embracing these LSIs, teams can design scalable, interoperable systems that balance local inference with cloud power for resilient, efficient operations.
Edge computing: Real-time data processing at the edge and latency reduction
Edge computing moves computation closer to where data is created, enabling immediate insights and faster decisions. This shift highlights the edge computing benefits, including reduced network traffic, improved reliability, and the ability to act on data within milliseconds rather than waiting for cloud roundtrips. By processing at or near the source, organizations unlock real-time data processing at the edge and noticeable latency reduction.
Industries such as manufacturing, healthcare, and transportation demonstrate how edge data processing supports swift actions on the plant floor or in transit. Sensors and gateways perform initial analysis locally, sending only summaries or alerts to the cloud. The result is faster decisions, lower bandwidth use, and a more autonomous, secure workflow that aligns with the broader edge computing benefits.
Edge data processing: Local analytics for reliability and bandwidth efficiency
Edge data processing enables local analytics that optimize bandwidth use and reduce cloud costs. By filtering and aggregating data near its source, organizations experience latency reduction and can maintain responsive operations even when connectivity is imperfect. This approach supports real-time data processing at the edge while keeping the core data economy lean.
Keeping analytics near devices also strengthens data sovereignty and security. Local processing minimizes the exposure of sensitive information and reduces the need to shuttle large datasets upstream, thereby improving reliability and compliance as part of a broader edge computing benefits.
Edge AI at the edge: Turning sensors into smart decision-makers
Edge AI brings artificial intelligence directly to devices, enabling on-device inference and immediate decision-making. Running models locally accelerates actions, enhances privacy, and contributes to the edge computing benefits by avoiding unnecessary data movement. This setup supports real-time data processing at the edge and lowers latency through targeted computation.
In practice, edge AI powers applications such as surveillance image recognition, predictive maintenance for industrial equipment, and smart retail experiences. By performing inference at the edge, organizations reduce bandwidth requirements and gain faster, context-aware responses that are resilient to network variability.
Latency reduction strategies for scalable edge architectures
A core goal of scalable edge architectures is latency reduction. By distributing compute closer to devices, organizations avoid round-trips to centralized clouds and enable real-time data processing at the edge even during peak workloads. This accelerates control loops, safety systems, and automated responses across sites.
To realize these benefits, teams optimize models for edge hardware, leverage hardware acceleration, and design lean data pipelines. Robust device management and secure deployment practices ensure that latency improvements persist as the edge footprint expands and new workloads are added.
Hybrid models: Integrating edge, fog, and cloud for resilient workloads
Hybrid models blend edge, fog, and cloud resources so that critical tasks run where speed matters while heavier analytics and historical processing migrate to the cloud. This arrangement preserves edge computing benefits like low latency and offline operation, while using central resources for scale and long-term data insights.
Orchestration, standards, and interoperable interfaces enable seamless data sharing across layers. By enabling edge data processing to feed cloud analytics and vice versa, organizations achieve a balanced, flexible architecture that supports real-time data processing at the edge where it matters most.
Security, governance, and data sovereignty in distributed edge systems
Security and governance are central to distributed edge systems. Local processing helps protect data privacy and meets regulatory requirements, underscoring the edge computing benefits. A layered security strategy — including authentication, encryption, and secure firmware updates — reduces risk across thousands of distributed devices.
Operational resilience depends on scalable device management, consistent update practices, and clear data governance policies. Addressing interoperability across vendors and standards ensures reliable, secure, and compliant edge deployments that support real-time data processing at the edge in diverse environments.
Frequently Asked Questions
What is edge computing and how does it differ from cloud computing?
Edge computing processes data at or near its source (sensors, gateways, local servers) instead of sending everything to a central cloud. This edge data processing reduces latency, lowers network traffic, and enables faster, more autonomous decisions. It complements cloud computing in a hybrid model, rather than replacing it.
What are the core benefits of edge computing for businesses?
Key edge computing benefits include latency reduction and real-time data processing at the edge, enabling faster control and responses. Additional advantages are bandwidth optimization, improved data sovereignty and security, offline operation, and scalable deployment.
How does edge AI improve decision-making at the edge?
Edge AI runs AI models locally for inference, enabling real-time insights without sending raw data to centralized servers. This supports latency reduction, privacy, and resilience, with use cases such as image recognition, predictive maintenance, and personalized experiences at the edge.
What infrastructure is required to support edge data processing?
A mix of sensors and gateways, micro data centers or local servers, and an edge orchestration/management layer. Secure communications, device management, and governance are essential to handle updates and security across distributed devices. Many organizations use a hybrid setup that pairs edge processing with cloud workloads for non-latency tasks.
What are real-world applications of edge computing across industries?
In manufacturing, edge data processing enables predictive maintenance and real-time quality control. Healthcare uses edge to monitor patients with privacy-preserving processing. Autonomous vehicles rely on edge AI for safety decisions, while retail and smart cities leverage local analytics for personalized service, improved security, and real-time insights.
What challenges should organizations anticipate with edge computing?
Common challenges include security and a larger attack surface, scalable device management, interoperability and standards, upfront costs for hardware and software, and the need for skilled personnel. A hybrid edge–cloud model can help balance advantages, but it requires careful planning and governance.
| Section | Key Points |
|---|---|
| Introduction | |
| Introduction |
|
| What is edge computing? |
|
| Why is edge computing popular today? |
|
| Core benefits of edge computing |
|
| Edge computing in practice: real-world applications across industries |
|
| Edge AI: bringing intelligence to the edge |
|
| Challenges and considerations |
|
| The future of edge computing: convergence and hybrid models |
|
Summary
Edge computing is redefining data processing by shifting where and how we analyze information. It enables real-time decisions at or near the data source, reducing latency and improving reliability. By distributing compute across edge devices, gateways, and local servers, businesses can enhance security, preserve data sovereignty, and build more resilient systems. This distributed approach supports critical applications—from industrial automation to healthcare and transportation—while enabling Edge AI insights without over-relying on centralized clouds. As organizations plan scalable, secure edge infrastructures, Edge computing will remain a strategic pillar for faster, smarter, and more autonomous digital ecosystems.

